Pratik BarjatiyaBoosting Big Data Analytics with Apache Spark GraphXTable of contentsJun 7, 2023Jun 7, 2023
InData And BeyondbyPratik BarjatiyaUnleashing the Potential of Apache Spark GraphX for Graph ProcessingTable of contentsJun 7, 20232Jun 7, 20232
Pratik BarjatiyaThe Ultimate PySpark Cheat Sheet: A Data Engineer’s Best FriendAre you a data engineer looking to master PySpark and streamline your data processing tasks? Look no further! In this comprehensive cheat…Apr 5, 2024Apr 5, 2024
Pratik BarjatiyaUnleashing the Power of Data: How Big Data and Data Science are Revolutionizing Decision Making in…In today’s fast-paced world, businesses are generating massive amounts of data every second. From customer preferences to sales figures…Apr 23, 2023Apr 23, 2023
InData And BeyondbyPratik BarjatiyaKappa Architecture: Stream Processing in Big Data AnalyticsKappa Architecture is a variant of the Lambda Architecture that has gained popularity in the big data world. It was introduced by Jay Kreps…Apr 23, 2023Apr 23, 2023
Pratik BarjatiyaMaximizing Big Data Potential: Batch and Stream Processing, Data Pipelines, and Distributed Cloud…The explosion of data in recent years has transformed the way businesses operate. The massive amount of data generated every day is both a…Apr 21, 2023Apr 21, 2023
Pratik BarjatiyaData Pipelines: The Backbone of Modern Data ArchitectureIntroductionApr 20, 2023Apr 20, 2023
Pratik BarjatiyaHow to Optimize E-commerce using Data-Driven Segmentation and Personalized RecommendationsIn the world of e-commerce, every click, view, and purchase represents an opportunity for businesses to better understand their customers…Apr 11, 2023Apr 11, 2023
Pratik BarjatiyaUnleashing the Power of Machine Learning with Spark ML: An Interactive JourneyWelcome to the world of machine learning with Spark ML! In this blog post, we’ll embark on an interactive journey to explore the…Aug 25, 2023Aug 25, 2023
InData And BeyondbyPratik BarjatiyaUnleashing the Power of Machine Learning with Spark ML and PySpark MLTable of contentsAug 25, 2023Aug 25, 2023
InData And BeyondbyPratik BarjatiyaCustomer Segmentation Using K-Means Clustering with PySpark: Unveiling Insights for Business…Introduction to Customer SegmentationJun 27, 2023Jun 27, 2023
InData And BeyondbyPratik BarjatiyaMastering PySpark ‘when’ Statement: A Comprehensive GuideI. IntroductionJun 13, 20231Jun 13, 20231
Pratik BarjatiyaMastering PySpark Joins, Filters, and GroupBys: A Comprehensive GuideDiscover the power of PySpark joins, filters, and groupBys for efficient big data processing. Learn practical techniques and code snippets…Jun 13, 2023Jun 13, 2023
Pratik BarjatiyaPySpark Overview: Introduction to Big Data Processing with PythonIn today’s data-driven world, handling massive volumes of data efficiently is crucial. PySpark, the Python library for Apache Spark, offers…May 31, 20231May 31, 20231
InData And BeyondbyPratik BarjatiyaPySpark: Empowering Python Developers in Distributed Big Data ProcessingIn the era of big data, processing massive volumes of data efficiently and quickly is crucial for organizations across industries.May 28, 2023May 28, 2023
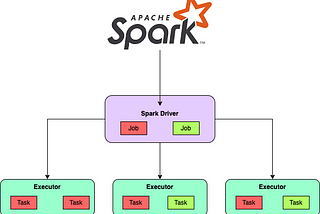
Pratik BarjatiyaDemystifying Spark Jobs, Stages, and Tasks: A Simplified GuideApache Spark has revolutionized big data processing with its lightning-fast speed and scalability. As you delve into Spark, you’ll…May 28, 20231May 28, 20231
Pratik BarjatiyaApache Spark Performance Tuning Interview Questions and AnswersHere are some Apache Spark Performance Tuning Interview Questions:May 21, 2023May 21, 2023
InData And BeyondbyPratik BarjatiyaImplementing a Data Lake and Data Ingestion System with CDC Pipeline Using Kafka and SparkYou can create a CDC pipeline using below architecture.Jan 13, 2023Jan 13, 2023
InDataDrivenInvestorbyPratik BarjatiyaOptimizing Spark Performance with AQE: A Deep Dive into Apache Spark’s Adaptive Query ExecutionApache Spark is an open-source, distributed computing system used for big data processing. It is widely used for tasks such as data…Mar 14, 20232Mar 14, 20232
Pratik BarjatiyaMastering Data Processing with Apache Spark’s Catalyst OptimizationApache Spark is an open-source distributed computing system used for big data processing, analytics, and machine learning. It has gained…Apr 20, 2023Apr 20, 2023