PySpark Overview: Introduction to Big Data Processing with Python
In today’s data-driven world, handling massive volumes of data efficiently is crucial. PySpark, the Python library for Apache Spark, offers a scalable and high-performance solution for big data processing. This blog post provides an overview of PySpark, highlighting its key features, architecture, and integration with Python. Whether you are a data scientist, data engineer, or big data enthusiast, understanding PySpark can open up new possibilities for analyzing and processing large datasets.

Table of Contents
- What is PySpark?
- Key Features of PySpark
- PySpark Architecture
- PySpark and Python Integration
- Data Processing with PySpark
- PySpark Libraries and Ecosystem
- PySpark for Machine Learning
- Scaling PySpark Applications
- PySpark Best Practices
- Conclusion
What is PySpark?
Key Features of PySpark
PySpark offers a comprehensive set of features that make it a powerful tool for distributed data processing. Its scalability, fault tolerance, in-memory processing capabilities, support for various data formats, and compatibility with other Spark components make it a popular choice for big data applications. Whether you are working with large-scale datasets, real-time streaming data, or implementing machine learning algorithms, PySpark provides the flexibility and performance needed to tackle complex data challenges.
- Scalability and Handling Large-scale Data: PySpark is designed to handle massive volumes of data. It can efficiently process and analyze datasets ranging from gigabytes to petabytes, making it suitable for big data applications. PySpark leverages the distributed computing capabilities of Apache Spark, allowing computations to be distributed across multiple nodes in a cluster.
- Fault Tolerance: PySpark provides fault tolerance by keeping track of the lineage of each RDD (Resilient Distributed Dataset). If a node fails during the computation, Spark can reconstruct the lost RDD partitions using the lineage information. This ensures that data processing can continue seamlessly without the risk of data loss.
- In-Memory Processing: PySpark leverages in-memory computing, which significantly speeds up data processing. It stores the intermediate data in memory, reducing the need for disk I/O operations and enhancing overall performance. This feature is especially beneficial for iterative algorithms and interactive data analysis.
- Support for Various Data Formats: PySpark supports a wide range of data formats, including CSV, JSON, Parquet, Avro, and more. It provides built-in libraries and APIs to read, write, and process data in these formats. This flexibility allows users to work with diverse data sources and seamlessly integrate with existing data ecosystems.
- Compatibility with Spark Components: PySpark seamlessly integrates with other Spark components, enabling users to leverage additional functionalities. For example, it integrates with Spark SQL, allowing SQL-like querying and processing of structured and semi-structured data. PySpark also integrates with MLlib, Spark’s machine learning library, providing a powerful platform for building and deploying machine learning models at scale.
- Language Interoperability: PySpark supports multiple programming languages, including Python, Scala, Java, and R. This allows teams with different language preferences to collaborate and leverage their preferred languages for data processing and analysis tasks. Python, being a popular language for data analysis and machine learning, makes PySpark a favorable choice for Python developers.
- Streaming and Real-time Processing: PySpark provides support for streaming data processing through Spark Streaming. It allows users to process real-time data streams and perform near-real-time analytics, enabling applications such as real-time monitoring, fraud detection, and more.
PySpark Architecture
PySpark is built on top of Apache Spark, an open-source distributed computing framework. Understanding the architecture of PySpark is crucial for effectively utilizing its capabilities for distributed data processing. Let’s delve into the key components of the PySpark architecture:
- Driver Program: The Driver Program is the main entry point for PySpark applications. It runs the user’s code and coordinates the execution of tasks across the cluster. The Driver Program communicates with the Cluster Manager to allocate resources, schedule tasks, and monitor their progress. It also manages the SparkContext, which is the entry point for interacting with Spark from Python.
- Cluster Manager: The Cluster Manager is responsible for managing the resources and scheduling tasks on a cluster of machines. It can be one of the supported cluster managers, such as Apache Mesos, Hadoop YARN, or Spark’s standalone cluster manager. The Cluster Manager allocates resources to the application based on the requested configuration and manages the distribution of tasks to the available workers.
- Executors: Executors are worker processes that run on the cluster nodes and perform the actual computations. They are responsible for executing the tasks assigned to them by the Driver Program. Executors manage the data partitions and cache intermediate results in memory for efficient processing. They communicate with the Driver Program and the Cluster Manager to receive tasks, report task status, and exchange data.
- Resilient Distributed Dataset (RDD): RDD is the fundamental data structure in PySpark. It represents an immutable distributed collection of objects across the cluster. RDDs are partitioned and distributed across multiple nodes in the cluster, allowing for parallel processing of data. RDDs are fault-tolerant, meaning they can recover from node failures by using their lineage information to reconstruct lost partitions.
PySpark’s architecture enables distributed data processing through the following steps:
- Data Loading: PySpark can read data from various sources such as Hadoop Distributed File System (HDFS), local file systems, databases, and more. The data is partitioned and distributed across the cluster.
- RDD Creation: PySpark transforms the loaded data into RDDs, which are resilient, distributed collections of objects. RDDs can be created from data in memory or by transforming existing RDDs through various operations like mapping, filtering, aggregating, and joining.
- Task Execution: The Driver Program splits the computation into smaller tasks and assigns them to the available Executors. Each Executor processes its assigned tasks independently, operating on the RDD partitions residing on its node. The computations are performed in parallel across the cluster, utilizing the available computing resources efficiently.
- Result Aggregation: The results of the executed tasks are collected from the Executors and aggregated by the Driver Program. The collected results can be further processed, analyzed, or stored as needed.
The PySpark architecture’s distributed nature enables scalable and efficient processing of large-scale datasets. By leveraging the power of distributed computing and in-memory processing, PySpark can handle complex data operations with high performance and fault tolerance. The RDD abstraction simplifies the distributed data processing model, allowing developers to focus on the logic of their data transformations and analysis tasks.
Overall, PySpark’s architecture provides a flexible and scalable framework for distributed data processing, making it an ideal choice for big data analytics and machine learning applications.
PySpark and Python Integration
PySpark seamlessly integrates with Python, making it a popular choice for Python developers who want to leverage the power of distributed computing for big data processing. PySpark provides Python APIs that allow developers to write Spark applications using familiar Python syntax. This integration brings together the simplicity and expressiveness of Python with the scalability and performance of Apache Spark. Let’s explore how PySpark enables Python developers to work with big data efficiently:
PySpark Python APIs
- PySpark provides a Python library called
pysparkthat exposes the Spark functionality through Python APIs. This library allows developers to interact with Spark's core components, such as SparkContext, DataFrame, and RDD, using Python code. - The
pysparklibrary provides a high-level interface that abstracts away the complexities of distributed computing, allowing Python developers to focus on data analysis and manipulation tasks. - PySpark supports both the interactive PySpark shell (pyspark) and Python script execution using the
spark-submitcommand.
Python Libraries Integration
- One of the major advantages of using PySpark is its seamless integration with the vast ecosystem of Python libraries. Python developers can leverage popular libraries such as NumPy, pandas, matplotlib, scikit-learn, and more for data analysis, machine learning, and visualization.
- PySpark allows you to convert between Spark DataFrames and pandas DataFrames, enabling you to take advantage of pandas’ rich data manipulation capabilities. This integration makes it easier to work with structured data in a familiar pandas-like manner.
- You can use Python libraries for advanced analytics, statistical modeling, and machine learning algorithms alongside PySpark. These libraries provide a wide range of tools and algorithms that can be applied to big data sets processed with PySpark.
UDFs and Custom Transformations
- PySpark allows you to define User-Defined Functions (UDFs) in Python, which can be applied to Spark DataFrames or RDDs. UDFs enable you to apply custom transformations or calculations on your data using Python code.
- With UDFs, Python developers can bring their domain-specific knowledge and expertise to the data processing pipeline, enhancing the capabilities of PySpark for specific use cases.
Interactive Data Exploration
- PySpark provides an interactive shell called pyspark, which allows you to interactively explore and analyze data using Python. This shell supports interactive querying, data manipulation, and visualization, making it convenient for data exploration and prototyping.
To leverage Python libraries in PySpark, you can use the pyspark.ml package for machine learning, the pyspark.sql package for working with structured data using DataFrames, and the pyspark.mllib package for working with RDDs. These packages provide a wide range of functions and methods to perform various data operations.
Here’s an example of leveraging Python libraries in PySpark:
from pyspark.sql import SparkSession
import pandas as pd
# Create a SparkSession
spark = SparkSession.builder.getOrCreate()
# Read data into a Spark DataFrame
data = spark.read.csv('data.csv', header=True)
# Convert Spark DataFrame to pandas DataFrame
pandas_df = data.toPandas()
# Perform data analysis using pandas functions
mean = pandas_df['column_name'].mean()
max_value = pandas_df['column_name'].max()
# Convert pandas DataFrame back to Spark DataFrame
data = spark.createDataFrame(pandas_df)
# Apply PySpark transformations and actions
result = data.filter(data['column_name'] > 0).select('column_name').collect()
# Perform machine learning using PySpark and Python libraries
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression
# Define feature columns and target column
assembler = VectorAssembler(inputCols=['feature1', 'feature2'], outputCol='features')
data = assembler.transform(data)
model = LinearRegression(featuresCol='features', labelCol='target')
trained_model = model.fit(data)
# Make predictions
predictions = trained_model.transform(data)
# Perform data visualization using Python libraries
import matplotlib.pyplot as plt
plt.plot(pandas_df['column_name'], pandas_df['target_column'])
plt.xlabel('Column Name')
plt.ylabel('Target Column')
plt.show()Data Processing with PySpark
PySpark provides powerful tools for data processing, allowing you to efficiently manipulate and analyze large-scale datasets. In this section, we’ll walk through the steps to read and process data using RDDs (Resilient Distributed Datasets) and DataFrames in PySpark, perform transformations and aggregations, and execute Spark SQL queries. Let’s dive into practical examples of data processing with PySpark:
- Data Loading: To start with, let’s assume we have a dataset stored in a file (e.g., CSV) and we want to load it into PySpark for processing. Here’s an example of how to read a CSV file using PySpark:
from pyspark.sql import SparkSession
# Create a SparkSession
spark = SparkSession.builder.getOrCreate()
# Read CSV file into a DataFrame
df = spark.read.csv('data.csv', header=True)- Data Transformation and Manipulation: Once the data is loaded into a DataFrame, you can perform various transformations and manipulations to prepare the data for analysis. PySpark provides a rich set of functions and methods for data transformation. Here are a few examples:
# Selecting columns
df.select('column1', 'column2')
# Filtering rows
df.filter(df['column'] > 100)
# Adding new columns
df.withColumn('new_column', df['column1'] + df['column2'])
# Grouping and aggregating data
df.groupBy('column').agg({'column': 'sum'})
# Sorting data
df.sort('column')- Spark SQL Queries: PySpark provides a SQL-like interface called Spark SQL, which allows you to execute SQL queries on DataFrames. This is useful when you are familiar with SQL syntax or when you need to perform complex queries. Here’s an example:
df.createOrReplaceTempView('my_table')
result = spark.sql('SELECT column1, COUNT(*) FROM my_table GROUP BY column1')
result.show()- Data Aggregations: PySpark offers several built-in functions for performing aggregations on data. These functions allow you to calculate statistics, apply mathematical operations, and derive insights from your data. Here are a few examples:
# Counting rows
df.count()
# Computing sum, average, maximum, minimum, etc.
df.agg({'column': 'sum'})
# Computing descriptive statistics
df.describe()- Data Output: After processing the data, you may need to store or export the results. PySpark provides various options to save the processed data, such as writing it to a file (e.g., CSV, Parquet) or storing it in a database. Here’s an example of how to save a DataFrame as a CSV file:
df.write.csv('output.csv', header=True)These are just a few examples of the data processing capabilities of PySpark. With its rich set of functions, you can perform complex data transformations, aggregations, and analytics on large-scale datasets efficiently. PySpark’s distributed computing capabilities enable it to handle big data processing tasks in parallel, making it a powerful tool for data processing and analysis.
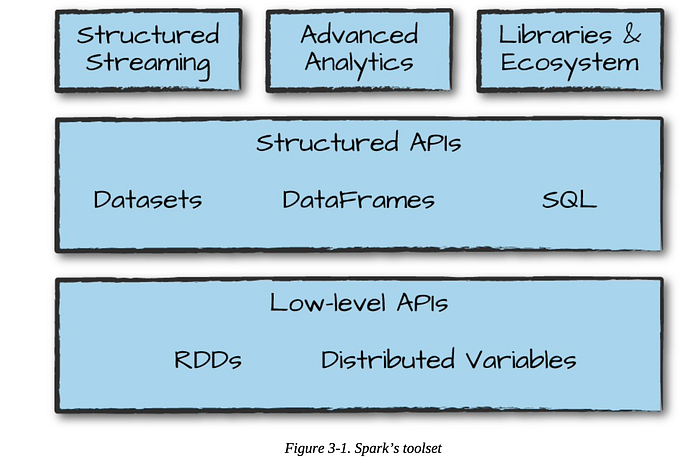
PySpark Libraries and Ecosystem
PySpark benefits from a rich ecosystem of libraries and extensions that enhance its functionality and allow developers to tackle a wide range of data processing and analysis tasks. These libraries leverage the power of Apache Spark’s distributed computing capabilities and provide specialized tools for real-time data processing, machine learning, graph processing, and more. Let’s explore some of the popular libraries in the PySpark ecosystem:
- Spark SQL: Spark SQL is a module in PySpark that provides a programming interface for working with structured and semi-structured data. It allows you to execute SQL queries on DataFrames and provides support for reading and writing data in various formats, including CSV, JSON, Parquet, and more. Spark SQL enables seamless integration of SQL-based operations with PySpark’s data processing capabilities.
- Spark Streaming: Spark Streaming is an extension of PySpark that enables real-time data processing and stream processing. It allows you to ingest and process data in near real-time from various sources like Kafka, Flume, and more. Spark Streaming provides high-level abstractions for processing streaming data, making it easy to perform transformations, aggregations, and window operations on data streams.
- MLlib: MLlib is PySpark’s machine learning library, which provides a rich set of algorithms and tools for scalable machine learning tasks. It includes various classification, regression, clustering, and recommendation algorithms, as well as tools for feature extraction, model evaluation, and hyperparameter tuning. MLlib leverages PySpark’s distributed computing capabilities to handle large-scale machine learning tasks efficiently.
- GraphX: GraphX is a graph processing library in PySpark that allows you to perform graph-based computations on large-scale datasets. It provides an abstraction for working with graphs and supports operations like graph construction, graph algorithms, and graph querying. GraphX is particularly useful for applications like social network analysis, fraud detection, and recommendation systems.
- SparkR: SparkR is an R package that enables R users to leverage the power of PySpark for distributed data processing and analysis. It provides an R API for interacting with Spark’s data structures and performing various operations. SparkR allows R users to scale their data analysis tasks and take advantage of PySpark’s distributed computing capabilities.
- PySpark Extensions: Apart from the core libraries, there are several third-party extensions and libraries that integrate with PySpark and extend its functionality. Some popular extensions include Koalas (provides a pandas-like API for PySpark), PySpark-DeepLearning (integrates deep learning libraries with PySpark), and GeoSpark (enables geospatial data processing in PySpark).
These libraries and extensions enhance PySpark’s capabilities and enable developers to tackle diverse data processing and analysis tasks. Whether you need to perform real-time stream processing, build machine learning models, process graph data, or work with R, the PySpark ecosystem offers a wide range of tools and libraries to support your requirements.
PySpark for Machine Learning
PySpark, with its MLlib library, provides a powerful and scalable platform for distributed machine learning. MLlib leverages PySpark’s distributed computing capabilities to process large-scale datasets and train machine learning models efficiently. Let’s explore some common machine learning tasks in PySpark and how to leverage MLlib for building and training models.
- Data Preparation: The first step in any machine learning task is data preparation. PySpark offers various tools for data preprocessing, including data cleaning, feature extraction, and transformation. You can use PySpark’s DataFrame API to manipulate and transform your data, perform feature engineering, handle missing values, and encode categorical variables. This ensures that your data is in the right format and ready for training.
- Model Building: PySpark’s MLlib provides a wide range of machine learning algorithms for classification, regression, clustering, and recommendation tasks. These algorithms are designed to work in a distributed computing environment, allowing you to train models on large datasets. You can use algorithms like Logistic Regression, Random Forest, Gradient Boosted Trees, Support Vector Machines (SVM), and more. MLlib also supports model selection and evaluation techniques to help you choose the best model for your data.
- Pipelines: PySpark’s MLlib supports the concept of pipelines, which are a sequence of data processing and modeling stages. Pipelines allow you to define a workflow that includes data preprocessing, feature extraction, model training, and evaluation. This helps in building scalable and reproducible machine learning workflows. Pipelines can be easily constructed using PySpark’s Pipeline API, enabling you to streamline your machine learning process.
- Model Training and Evaluation: PySpark’s MLlib provides tools for training and evaluating machine learning models. You can split your data into training and testing sets using PySpark’s data splitting functions. Then, you can train your models on the training data and evaluate their performance on the testing data. MLlib offers evaluation metrics for classification (e.g., accuracy, precision, recall), regression (e.g., mean squared error, R-squared), and clustering (e.g., silhouette score). This allows you to assess the quality of your models and make informed decisions.
- Model Deployment: Once you have trained and evaluated your models, PySpark makes it easy to deploy them in a production environment. You can save the trained models using MLlib’s model persistence functionality and load them later for making predictions on new data. PySpark also supports model serving through integration with other deployment frameworks like Apache Spark Serving, allowing you to scale your machine learning models and serve predictions at scale.
PySpark’s MLlib provides a comprehensive set of tools and algorithms for machine learning tasks, making it a powerful choice for scalable and distributed machine learning. With its distributed computing capabilities, you can process large datasets, train complex models, and deploy them in production environments. Whether you’re working on classification, regression, clustering, or recommendation tasks, PySpark with MLlib provides the necessary tools and infrastructure to tackle your machine learning projects at scale.
Scaling PySpark Applications
PySpark provides powerful tools and techniques for scaling your applications to handle large datasets and improve performance.
Here are some techniques for optimizing performance and improving scalability in PySpark:
- Data Partitioning: Partitioning your data is an effective technique to improve the performance of PySpark applications. By dividing your data into smaller partitions, you can distribute the processing workload across the cluster. PySpark allows you to explicitly specify the number of partitions when creating RDDs or DataFrames, or you can leverage automatic partitioning based on the underlying data source. Additionally, you can use partitioning techniques like range partitioning or hash partitioning to ensure data is evenly distributed across the cluster, optimizing parallel processing.
- Cluster Resource Tuning: To optimize performance, it’s important to tune the resources allocated to your PySpark cluster. You can configure various parameters like the number of executors, executor memory, driver memory, and executor cores to match the requirements of your application and dataset. Allocating sufficient resources ensures efficient utilization of the cluster’s computing power and memory, leading to faster processing. However, it’s important to strike a balance and avoid overallocating resources, as it can impact the stability and performance of the cluster.
- Caching and Persistence: PySpark provides the ability to cache and persist intermediate results or frequently accessed datasets in memory. Caching data reduces the need for recomputation and speeds up subsequent operations. You can use the
cache()orpersist()methods on RDDs or DataFrames to store them in memory or on disk. Caching is particularly beneficial when you have iterative algorithms or when you need to reuse the same dataset across multiple stages of your application. However, it's important to manage caching judiciously, considering the available memory resources and the frequency of data access. - Broadcast Variables: When working with PySpark, you may encounter scenarios where certain variables or data need to be shared across all the nodes in the cluster. In such cases, you can leverage broadcast variables. Broadcast variables are read-only variables that are efficiently distributed to each node in the cluster, reducing network communication overhead. By broadcasting commonly used data, such as lookup tables or reference data, you can avoid unnecessary data shuffling and improve the performance of join operations and other computations.
- Data Compression and Serialization: PySpark supports various compression codecs for reducing the size of data stored on disk or transferred over the network. Compressing data can significantly improve I/O performance and reduce storage requirements. You can choose appropriate compression codecs like Gzip or Snappy based on the nature of your data and the trade-off between compression ratio and CPU overhead. Additionally, PySpark provides serialization options like Pickle and Parquet, which can optimize data serialization and deserialization, further improving performance.
- Task Parallelism: PySpark takes advantage of task parallelism, where tasks are executed in parallel across the cluster. By default, PySpark automatically determines the optimal level of parallelism based on the available cluster resources. However, you can also fine-tune the level of parallelism by adjusting parameters like the number of partitions or the degree of parallelism. Ensuring sufficient parallelism allows for efficient utilization of cluster resources and faster processing of tasks.
By employing these techniques, you can optimize the performance and scalability of your PySpark applications. Remember that the effectiveness of each technique may vary depending on your specific use case and cluster configuration. It’s important to monitor and profile your applications to identify bottlenecks and make informed decisions to improve performance and scalability.
PySpark Best Practices
To ensure efficient and robust PySpark development, it’s important to follow best practices that optimize performance, maintain code quality, and improve overall productivity. Here are some PySpark best practices to consider:
Code Organization
- Structure your PySpark code into modular functions or classes to improve reusability and maintainability.
- Leverage object-oriented programming principles to encapsulate functionality and separate concerns.
- Use meaningful variable and function names to enhance code readability.
Resource Management
- Properly manage resources like memory, CPU cores, and disk space when configuring your PySpark cluster.
- Tune the cluster configuration parameters, such as executor memory and executor cores, based on the requirements of your application and dataset.
- Avoid overallocating resources, as it can lead to resource contention and degrade performance.
Data Serialization
- Choose appropriate serialization formats, such as Parquet, Avro, or ORC, to optimize data storage and processing.
- Serialization formats that are columnar or binary-based can significantly reduce I/O overhead and improve performance.
- Avoid using Python’s default Pickle serialization, as it can be slower and less efficient compared to optimized formats.
Error Handling
- Implement robust error handling mechanisms to gracefully handle exceptions and failures.
- Use try-except blocks to catch and handle specific exceptions that may occur during PySpark operations.
- Log and report errors appropriately to aid in debugging and troubleshooting.
Data Partitioning
- Partition your data appropriately to enable efficient parallel processing.
- Consider the size of data partitions, the number of partitions, and the distribution of data across partitions.
- Align the partitioning strategy with your data access patterns and processing requirements.
Broadcast Variables
- Utilize broadcast variables to efficiently share read-only data across nodes in the cluster.
- Identify and broadcast frequently accessed lookup tables or reference data to minimize data shuffling and improve performance.
Performance Optimization
- Leverage PySpark’s built-in optimization techniques, such as predicate pushdown, column pruning, and code generation, to improve query performance.
- Use appropriate join strategies, like broadcast joins or shuffle joins, depending on the size and nature of the datasets being joined.
- Avoid unnecessary data shuffling and minimize data movement between nodes in the cluster.
Monitoring and Debugging
- Monitor your PySpark applications using tools like Spark Web UI, Spark Monitoring Tools, or external monitoring systems.
- Monitor cluster metrics, job progress, and resource utilization to identify performance bottlenecks or issues.
- Utilize logging and debugging techniques to troubleshoot and diagnose any issues in your PySpark code.
By following these best practices, you can optimize performance, enhance code maintainability, and ensure a robust PySpark development process. It’s important to continually evaluate and refine your practices based on the specific requirements of your applications and the evolving needs of your data processing workflows.
PySpark plays a crucial role for big data processing and enabling scalable and distributed data analysis. I encourage readers to explore PySpark further and harness its capabilities for their big data projects.
I hope this can be useful for you. If you like this, and love to learn more about Data Engineering and Data Science, Do follow me.
In case of questions/comments, do not hesitate to write in the comments below or reach me directly through LinkedIn or Twitter.
You can also subscribe to my new articles.